Modal datatypes and codatatypes
In multimodal Narya, the modal operators are not built in, but rather are defined by the user as special cases of modal datatypes and codata/record types (just as Σ-types, for instance, are user-defined as particular record types). However, I’m running into some interesting questions of notation and typechecking when specifying these.
Modal datatypes
Like most type formers, modal operators can be classified as positive or negative. The positive ones are simpler and were the only ones included in the original multimodal dependent type theory. If □ is a positive modal operator, the idea is that a variable of type □ A can be “destructed” into an ordinary variable of type A that is annotated by the modality (corresponding to) □. In premise-conclusion type theory syntax, this is written as follows (from the MTT paper):
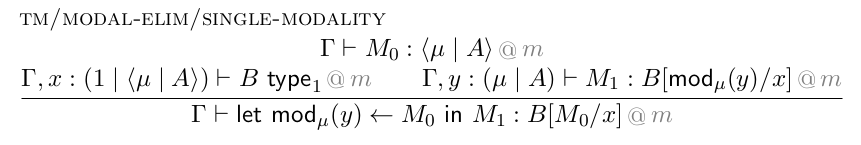
The main thing to note is how we replace the element M₀ of the modal type ⟨μ|A⟩ by a variable y that belongs to A but is annotated with the modality μ.
In multimodal Narya, positive modalities are not built-in, but can be defined by the user as a special case of a datatype with modal constructor(s). More generally, any of the arguments of a constructor can be annotated with a nontrivial modality, in which case when we match against that constructor, the pattern variable corresponding to that argument becomes similarly annotated. For instance, here’s a definition of an ordinary positive modal operator:
def □ (A :□| Type) : Type ≔ data [
| box. (x :□| A) ]
There is some punning going on here: the □ in the annotations :□| is the name of a modality (a morphism in the mode theory 2-category), which lives in a different namespace from user-defined constants, while the □ being defined is a user-defined constant (a modal datatype). I regard the possibility of such punning as a good argument for this notation for modal variable annotations, although of course it allows the user to shoot themselves in the foot by creating mismatches instead.
Given this definition, here is the proof that □ is functorial:
def □map (A B :□| Type) (f :□| A → B) (u : □ A) : □ B ≔ match u [
| box. x ↦ box. (f x) ]
In the single branch of this match, the variable x is □-annotated. Therefore, since f is also □-annotated, f x is also, and thus we can apply the constructor box. to it. (More precisely, the argument of the constructor box. is checked in a □-locked context, and we can access f and x in that context because their annotation matches the lock.)
This is great, but to get all the desired behavior of modal operators in general we need a stronger version of their elimination rule:
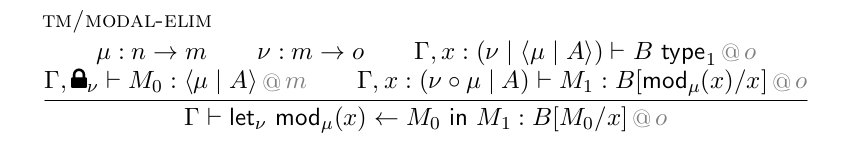
The difference here is that the term M₀ in the modal type ⟨μ|A⟩ is in a context that’s locked by some other modality ν, and then the variable x that it’s destructed into is annotated by the composite modality ν ∘ μ. This generality is necessary, for instance, when proving that modal types depend functorially on modes: if μ and ν are composable modalities, then to define a map from ⟨ ν | ⟨μ|A⟩ ⟩ to ⟨ ν ∘ μ | A ⟩ we first destruct on ν, and then we get an element of ⟨μ|A⟩ annotated by ν and we have to destruct that, requiring the above generalized elimination rule. This extra modality ν is sometimes called a “window” modality because we “look through it” to find the modality μ to destruct.
The question is, (how) should the window modality should be notated in a Narya match? If we are matching against a free variable, there is no need to notate it at all, since the context annotation on that variable must also be the window modality. But Narya also allows matches on arbitrary terms, and in that case the term doesn’t determine the window modality; indeed, we can’t even typecheck the term until we know the window modality.
Here are some possibilities I can think of for notating a window modality ◇:
match (M :◇| _) [ box. x ↦ ? ]
match M :◇| _ [ box. x ↦ ? ]
match M return (_ :◇| _) ↦ _ [ box. x ↦ ? ]
match M through ◇ [ box. x ↦ ? ]
match M under ◇ [ box. x ↦ ? ]
match M behind ◇ [ box. x ↦ ? ]
The first three don’t require any new keywords, only re-using the same variable annotation syntax. (The return clause is necessary for a dependent match against a non-variable term anyway, and is allowed for non-dependent matches with a _ as the output.) These three syntaxes seem logical to me, but I think they’re also a bit ugly. The discriminee of a match must synthesize a datatype, so under normal circumstances it would never need to be ascribed; so we can put a _ there as the type, but that looks noisy. We could allow putting the actual type there instead too, of course, but that would nearly always be redundant information.
The last three look less ugly to me, but they all involve introducing a new keyword such as through, under, or behind.
Anyone have any opinions?
Modal codata and record types
Negative modalities were introduced to an MTT-like theory in Modalities and Parametric Adjoints, and appear to require more structure on the relevant modality. The original paper used a parametric right adjoint, but using ordinary adjoints is simpler and covers the majority of examples, and that’s what I’m planning for multimodal Narya. In this case, the rules as I wrote them in Semantics of multimodal adjoint type theory are:
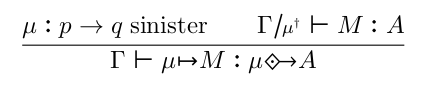
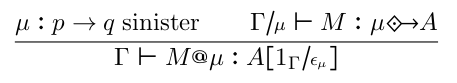
To be “sinister”, a modality μ must have a right adjoint μ†. The first, introduction, rule, is then the same as that for the positive modality associated to μ†; but the elimination rule uses μ instead.
In multimodal Narya, negative modalities are also not built-in, but can be defined by the user as a special case of a codata or record type with modal fields. And more generally, any of the fields of a codata or record type can be annotated by an adjunction of modalities.
But since there are two modalities in an adjunction, it’s already not entirely obvious how to notate the definition of such a codatatype. If the adjunction is ♭ ⊣ ♯ as in spatial type theory, then we could annotate the “self variable” of the field by the left adjoint ♭:
def ♯ (A : Type) : Type ≔ codata [
| (x :♭| _) .unsharp : A ]
The annotation by ♭ makes sense because in the elimination rule, i.e. when projecting out the field of an element of ♯ A, that element must be in a ♭-locked context. Annotating the self variable with its type is not currently allowed, but it would also be required if we wanted to implement “indexed codatatypes”.
However, we could instead try to annotate the output by the right adjoint:
def ♯ (A : Type) : Type ≔ codata [
| x .unsharp :♯| A ]
This annotation makes sense because in the introduction rule, i.e. when defining an element of ♯ A, the value of .usharp must be defined in a ♯-locked context, i.e. it “has type” :♯| A.
One problem with the second version is that the :♯| notation conflicts with the use of | to separate multiple fields of a codatatype, especially if the modality ♯ is replaced by a composite of named generating modalities, or has a longer name. This seems like a poor reason to reject it in the abstract (since we could change that notation instead), but we need some reason to choose one or the other.
Anyway, there’s a more serious problem with modal codatatypes. In Narya, field names are not scoped: when you write x .fst, Narya doesn’t know what codata or record type fst refers to until it synthesizes a type for x and inspects its definition. This generally works perfectly with bidirectional type checking, and means you can freely use fields of the same name for different record types without any worry about whether they will conflict or which of them is “opened” at any time. (Similarly, constructors don’t know what datatype they belong to, and hence must always be used in a checking context.)
However, in order to synthesize a type for x, Narya needs to know its context. And in the case of a modal field, the element being projected out of is supposed to be typechecked/synthesized in a locked context. So how should Narya figure out the modality to lock by?
One option would be to continue overloading modal ascription syntax:
(x :♭| _) .unsharp
This has the same pros and cons as the similar syntaxes for window modalities in match, above.
Another option would be to incorporate the modality in the name of the field:
x .♭.unsharp
Adding information to field names (which never contain internal periods themselves) has some precedent in the syntax for higher coinductive types (and although that syntax is arguably ugly itself, I haven’t thought of anything better). And we could also use this in defining modal codatatypes:
def ♯ (A : Type) : Type ≔ codata [
| x .♭.unsharp : A ]
However, if we did this, there would be a potential conflict with higher coinduction: a field declaration like .♭.ee could mean either a ♭-modal field named ee or an ee-dimensional higher field named ♭ (both dimension letters and modality names belong to different namespaces than field names). The latter could be disambiguated by .♭..e.e, though, so we could default .♭.ee to mean the former (and I think actual ambiguity would be exceedingly unlikely to arise in practice).
Finally, another approach would be to try to synthesize “just enough” of x to find which codatatype it belongs to, and then inspect that to find the modality to lock its context to actually synthesize the whole thing. However, in general “just enough” couldn’t be guaranteed to be any less work than synthesizing the whole thing, so it seems like this could add significant extra overhead to typechecking.
We could probably manage it so that if x synthesizes fully in an unlocked context (as for an ordinary non-modal field), it doesn’t need to be synthesized twice, so this wouldn’t impact performance of non-modal fields. But if we did take this approach, it would probably be a good idea to also allow something like (x :♭| _) .unsharp, to allow the user to eliminate the double typechecking and improve performance with an explicit annotation.
Anyone have any thoughts?
Comments
Comments use giscus, so you will need a github account and to authorize giscus to post on your behalf.